n-gramas
Mon 10 January 2011 Tags: labs
n-gramas es un buscador que permite explorar las tendencias en los artículos periodísticos de Colombia. Al buscar un término se puede ver con qué frecuencia ha aparecido durante los últimos años y compararlo con otros. Las búsquedas se hacen sobre una muestra del archivo de la revista Semana, que incluye artículos publicados desde 1982 hasta julio de 2010.
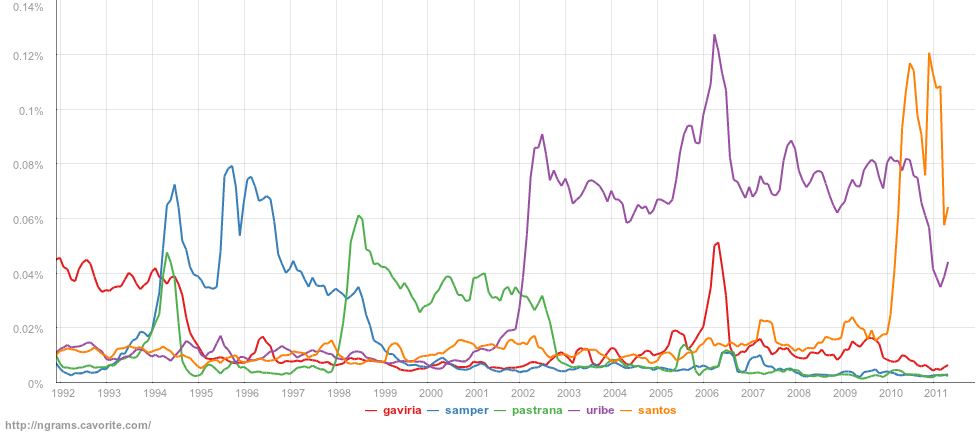
La idea surgió a partir del Google Books Ngram Viewer y el análisis que hice para tratar de averiguar el origen de la expresión “el tema de“. En ese momento noté que, en lugar de hacer el análisis para una sólo caso, era más más interesante buscar las expresiones más frecuentes para ver cuáles eran sido los temas que habían recibido más atención en la prensa. Depués de recibir un par de comentarios y ver el proyecto de Google, quise hacer mi propia versión para ver las tendencias de los medios locales.
Me da gusto saber que muchas personas han utilizado n-gramas. Desde su publicación (20 de diciembre de 2010) se han hecho cerca de 3.700 búsquedas. Gran parte de las visitas (34%) han llegado través de Twitter, que ha sido el principal medio en donde se ha discutido sobre el buscador. La columna de Alejandro Gaviria en El Espectador (comentarios) dio a conocer el buscador, tal vez, a una nueva audiencia y cerca del 23% de las visitas se hicieron siguiendo el enlace que publicó.
En cuanto a la implementación del buscador, ésta es bastante sencilla. La parte más importante es el índice en donde se almacenan las secuencias de palabras (n-gramas) y la cantidad de veces que cada secuencia aparece en los artículos publicados en un año. Actualmente el índice incluye las secuencias de hasta 5 palabras y, con el fin de reducir su tamaño, únicamente se tienen en cuenta aquellas que aparecen más de 10 veces en todo el año. El índice tiene 189.322 n-gramas que aparecen en los 113.428 artículos que descargué de Semana. Ya que por ahora no estoy agregando nuevos artículos, el índice no se actualiza periódicamente.
Para la construcción del índice utilicé gran parte de los programas que había escrito para el proyecto de el tema de y los adapté para encontrar todas las secuencias de términos. El más importante de los cambios lo hice para mejorar la separación de los textos en frases. Inicialmente había utilizado una estrategia trivial basada en expresiones regulares, pero luego la cambié por una que utiliza un modelo construido con la librería opennltk a partir de los resultados del método Punkt, incluído en NLTK.
Aunque la muestra de documentos no es muy grande, analizar los textos y encontrar los n-gramas es un proceso que tardaba mucho tiempo. Por ejemplo, las primeras pruebas que hice en mi computador personal se demoraba por lo menos 5 horas. Para poder ejecutarlo en menos tiempo, utilicé Hadoop para distribuir el procesamiento en un cluster de servidores y así pude obtener los resultados en menos de un par de horas.
Sin haberlo pensando mucho, este proyecto resultó ser mucho más interesante de lo que había esperado. Por eso, y por la atención que ha recibido, voy a seguir trabajando en él. Por ahora tengo varias ideas para mejorar n-gramas y hacer más con los datos. Por ejemplo, voy agregar documentos de otros medios y también quiero análizar mejor los datos para encontrar términos relacionados y detectar correlaciones entre ellos. Vamos a ver qué otras cosas puedo hacer.